How to use¶
The library offers a DAFSA object to compute automata, along with
methods for checking a sequence acceptance and for exporting the graph.
A minimal usage is shown here:
>>> from dafsa import DAFSA
>>> d = DAFSA(["tap", "taps", "top", "tops", "dibs"])
>>> print(d)
DAFSA with 8 nodes and 9 edges (5 inserted sequences)
+-- #0: 0(#1/5:<d>/1|#5/5:<t>/4) [('d', 1), ('t', 5)]
+-- #1: n(#2/1:<i>/1) [('i', 2)]
+-- #2: n(#3/1:<b>/1) [('b', 3)]
+-- #3: n(#4/1:<s>/1) [('s', 4)]
+-- #4: F() []
+-- #5: n(#6/4:<a>/2|#6/4:<o>/2) [('o', 6), ('a', 6)]
+-- #6: n(#7/4:<p>/4) [('p', 7)]
+-- #7: F(#4/4:<s>/2) [('s', 4)]
Note how the resulting graph includes the 5 training sequences, with one
start node (#0) that advances with either a t (observed four
times) or a d symbol (observed a single time), a subsequent node to
t that only advances with a and o symbols (#1), and so on. More
information on how to interpret the structure of a DAFSA are given in the
following subsections.
The structure is much clearer with a graphical representation:
>>> d.write_figure("example.png")
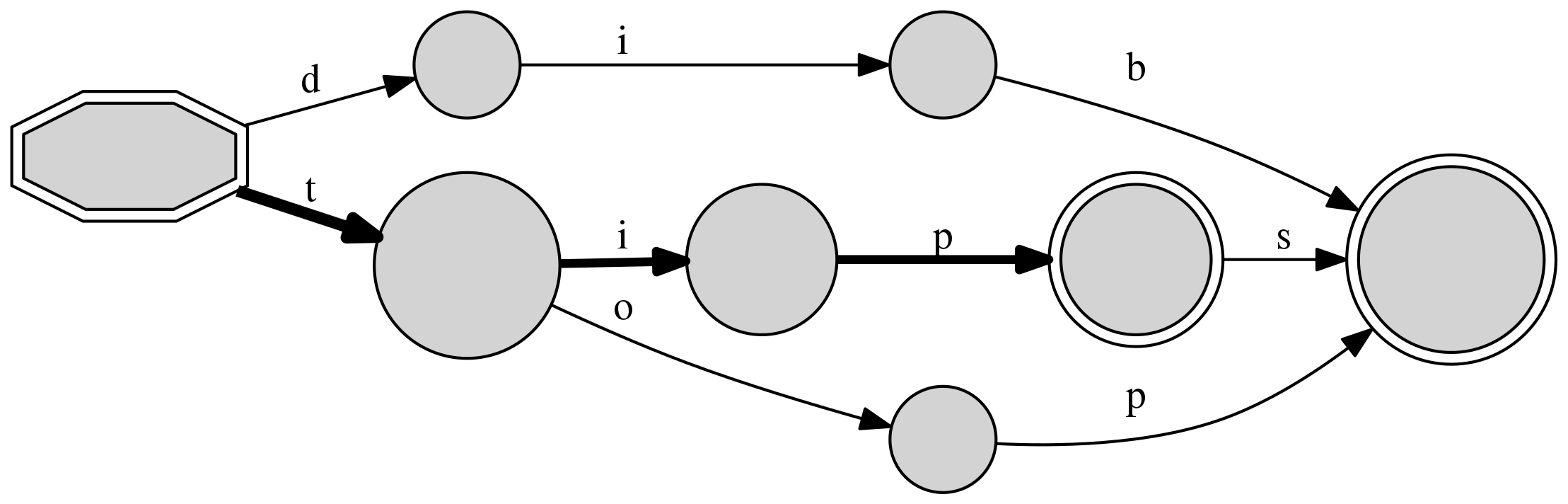
A DAFSA object allows to check for the presence or absence of a sequence in its structure, returning a terminal node if it can find a path. If the structure was computed using frequency weights, as by default, the cumulative path weight is also returned.
>>> d.lookup("tap")
(F(#4/4:<s>/2), 10)
>>> d.lookup("tops")
(F(), 12)
>>> d.lookup("tapap") is None
True
>>> d.lookup("ta") is None
True
Besides a number of alternatives for exporting visualizations, the structures
can also be exported as networkx graphs:
>>> d.to_graph()
<networkx.classes.graph.Graph object at 0x7f51d15b7ac8>
The library includes a command-line tool for reading files with lists of sequences, with one sequence per line:
$ cat resources/dna.txt
CGCGAAA
CGCGATA
CGGAAA
CGGATA
GGATA
AATA
$ dafsa resources/dna.txt -t png -o dna.png
Which will produce the following graph:

Sequences are by default processed one character at time, with each character assumed to be a single token. Pre-tokenized data can be provided to the library in the format of a Python list or tuple, or specified in source by using spaces as token delimiters:
$ cat resources/phonemes.txt
o kː j o
o r e kː j o
n a z o
s e n t i r e
s e n s o
ɡ u a r d a r e
a m a r e
v o l a r e
$ dafsa resources/phonemes.txt -t png -o phonemes.png
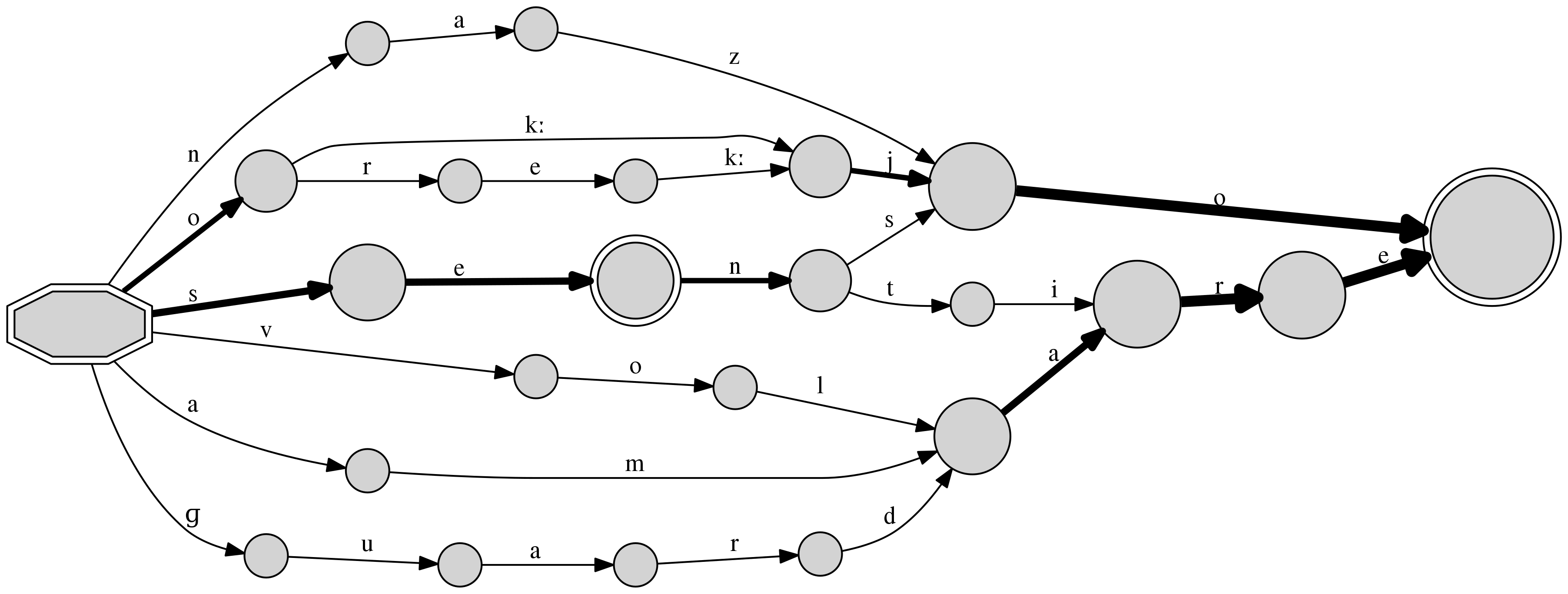
DAFSA structures can be exported in PDF, SVG, GLM, and DOT formats.
Walkthrough example¶
The simplest DAFSAs are capable of expressing only one string, linking its
sequence of characters from the first to the last. The creation of such a DAFSA
follows the procedures described above, here demonstrated with the string
tap:
>>> from dafsa import DAFSA
>>> d1 = DAFSA(["tap"])
>>> print(d1)
DAFSA with 4 nodes and 3 edges (1 inserted sequences)
+-- #0: 0(#1/1:<t>/1) [('t', 1)]
+-- #1: n(#2/1:<a>/1) [('a', 2)]
+-- #2: n(#3/1:<p>/1) [('p', 3)]
+-- #3: F() []
The printed textual representation confirms that only one sequence was
inserted, with three edges (or “transitions”, corresponding to the
three characters in our string) among four nodes (that is, a start node,
two transitional nodes, and a final node).
A unique but meaningless index (in this basic example, the numbers
from zero to three) identifies each node, an explicit textual
representation (such as
#1/1:<t>/1) that informs the type of node (0 for the start
node, n for “normal” nodes which are neither starts nor ends, and
F for final nodes), and a list of the edges originating in each node
(designed as a human-friendly, or at least programmer-friendly,
rendition of the textual representation).
In this first example, we have:
- A node of index 0 (
#0) and type0(that is, a start symbol), which, as indicated by the list[('t', 1)]can only transition (“advance”) with the charactert, moving to the node of index 1. - A node of index 1 and type
n(that is, a “normal” node), which can transition with the character a towards the node of index 2. - A similar node of index 2 and type
nas above, which can only transition with the character p towards node 3. - A node of index 3 and type
F(that is, a final one), which by definition ends a sequence.
We can easily generate a graphical representation:
>>> d1.write_figure("d1.png")
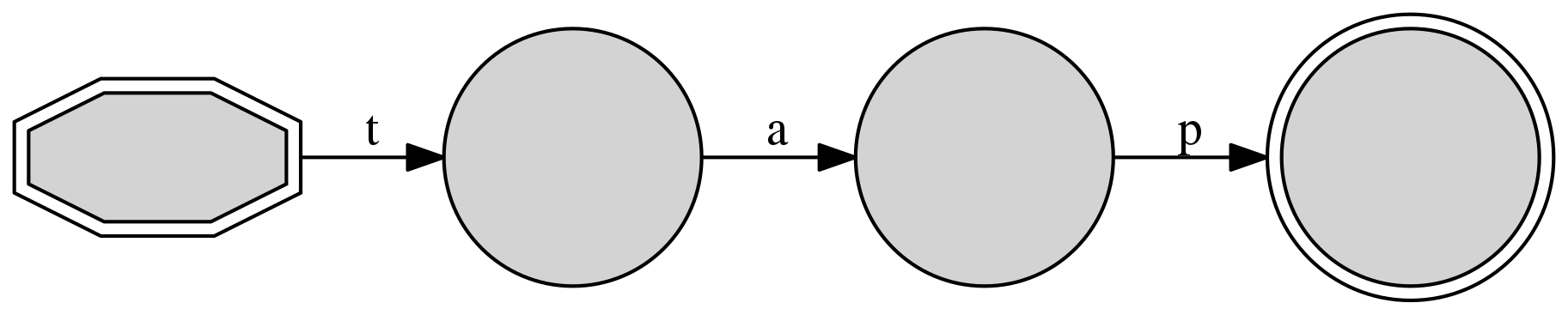
We can experiment with expanding the collection of sequences covered by the DAFSA.
If we include a second string dibs, without overlapping substrings
with tap,
we can observe how they only share the start and end symbols:
>>> d2 = DAFSA(["tap", "dibs"])
>>> print(d2)
DAFSA with 7 nodes and 7 edges (2 inserted sequences)
+-- #0: 0(#1/2:<d>/1|#5/2:<t>/1) [('d', 1), ('t', 5)]
+-- #1: n(#2/1:<i>/1) [('i', 2)]
+-- #2: n(#3/1:<b>/1) [('b', 3)]
+-- #3: n(#4/1:<s>/1) [('s', 4)]
+-- #4: F() []
+-- #5: n(#6/1:<a>/1) [('a', 6)]
+-- #6: n(#4/1:<p>/1) [('p', 4)]
Here the start symbol (node of index zero) carries two transition possibilities:
either the character d, which would move towards node #1,
or the character t, which would move towards
node #5. As the two strings share no information, each
of these initial transitions would lead to independent paths with
no inner alternatives (from d to
i, b, and s, in the first case, and from t to a
and p, in the
second). The structure only merges at the final symbol of index #4, which
can be reached both from node #3 (with a transition s) or from
node #6 (with a transition p).
The same information is expressed visually:
>>> d2.write_figure("d2.png")
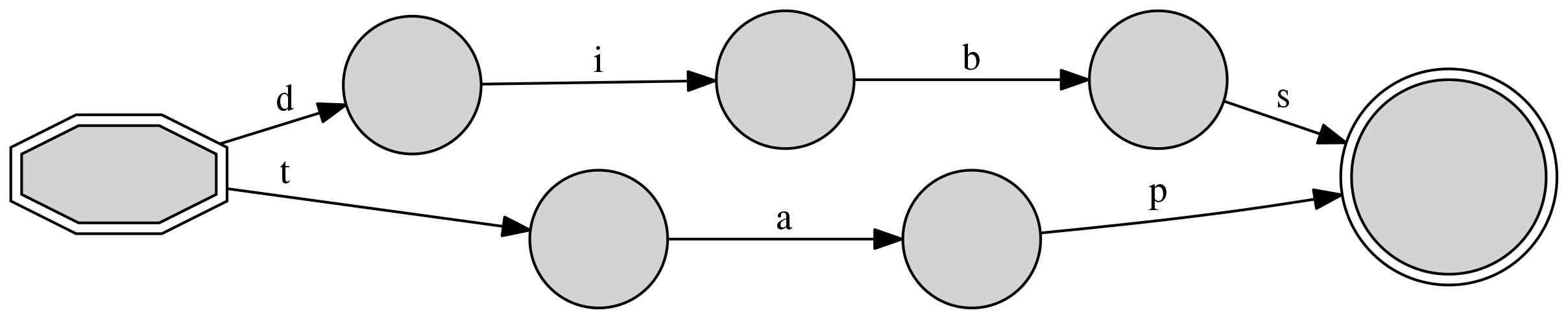
The convenience of DAFSAs becomes clearer if we extend this collection of
strings with elements that have overlapping material. For example,
by introducing the string taps, which overlaps with tap at the beginning
and with dibs at the end, we both trigger the automaton minimization,
highlighting overlapping regions, and collect frequencies for the number
of observed nodes and transitions.
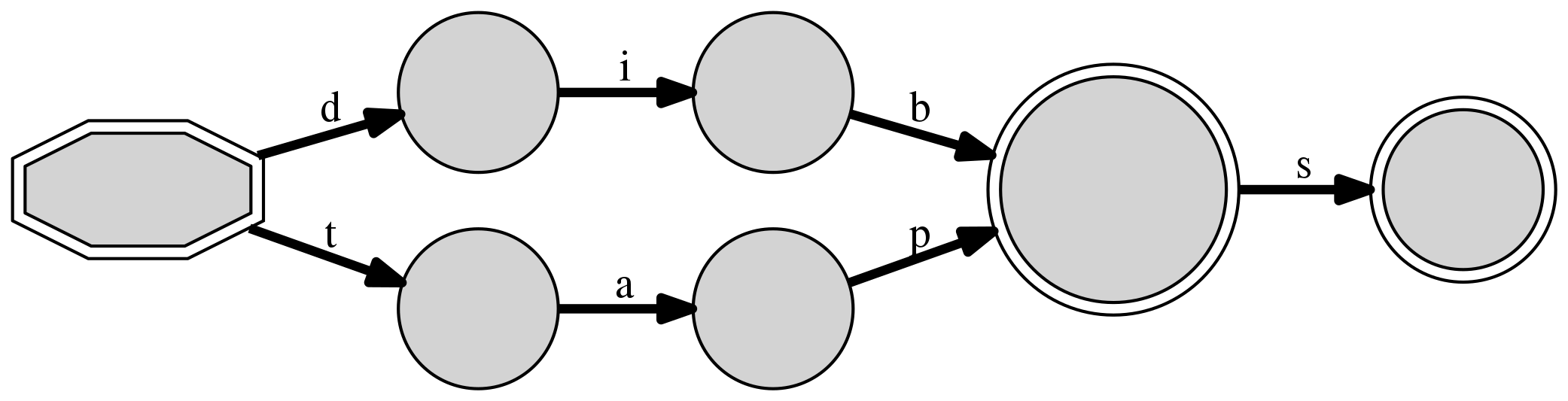
>>> d3 = DAFSA(["tap", "dibs", "taps"])
>>> print(d3)
DAFSA with 8 nodes and 8 edges (3 inserted sequences)
+-- #0: 0(#1/3:<d>/1|#5/3:<t>/2) [('t', 5), ('d', 1)]
+-- #1: n(#2/1:<i>/1) [('i', 2)]
+-- #2: n(#3/1:<b>/1) [('b', 3)]
+-- #3: n(#4/1:<s>/1) [('s', 4)]
+-- #4: F() []
+-- #5: n(#6/2:<a>/2) [('a', 6)]
+-- #6: n(#7/2:<p>/2) [('p', 7)]
+-- #7: F(#4/2:<s>/1) [('s', 4)]
The start node #0 has only two transitions, as in the previous
structure, because there are only two initial characters, t and
d. However, frequency information (the number to the right of the slash
in the unambiguous representation) informs that t is twice
as frequent. It is worth noting that we now have two final nodes,
#4 and #7, the latter of which is a “pass-through” final node, meaning
that a path can end at this node, treating it as a final one,
or advance to one of its transitions (here, an s to node #4),
using it as a normal node. Here, the pass-through is due to the
pair of strings tap/taps, as, once we reach node #7 with a transition
p from node #6, we can either terminate the string or add an s.
Node #4 might be at first surprising, as both dibs and
taps and with an s and one could expect them to share this
suffix. A careful examination shows that this is not possible, as the
final node #7 of taps is a pass-through: if dibs were to share
such node, the DAFSA would entail that a dib string is a member of this
set, which is false. Such a structure tends to be better
visualized with a graphical representation:
>>> d3.write_figure("d3.png")
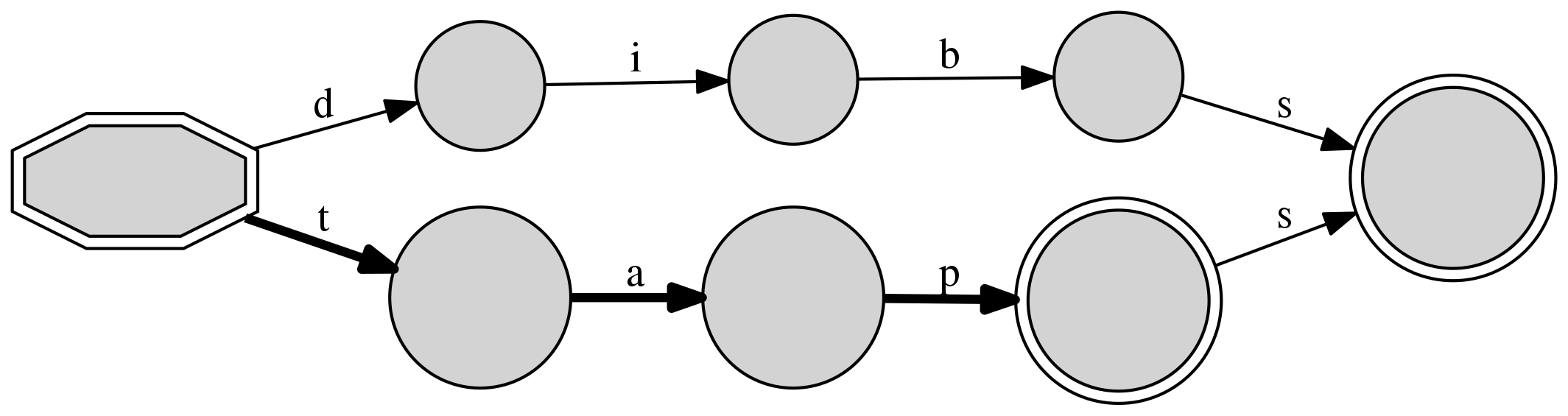
One perhaps counter-intuitive but welcomed property of DAFSAs, illustrated
by an expansion of
the above example, is that enlarging the group of strings can
reduce the automaton for their representation. If we add the “missing”
string dib to our collection, the resulting DAFSA is:
>>> d4 = DAFSA(["tap", "dibs", "taps", "dib"])
>>> print(d4)
DAFSA with 7 nodes and 7 edges (4 inserted sequences)
+-- #0: 0(#1/4:<d>/2|#5/4:<t>/2) [('t', 5), ('d', 1)]
+-- #1: n(#2/2:<i>/2) [('i', 2)]
+-- #2: n(#3/2:<b>/2) [('b', 3)]
+-- #3: F(#4/4:<s>/2) [('s', 4)]
+-- #4: F() []
+-- #5: n(#6/2:<a>/2) [('a', 6)]
+-- #6: n(#3/2:<p>/2) [('p', 3)]
Usage example for scientific analysis¶
We have learned how to use DAFSA and explored how to understand its
output. Users unfamiliar with the library might at this
point find it an intersting and handy tool without having a
precise idea of its purpose, also considering how
its documentation repeats that, while
this kind of automata is often used for space-efficient data storage,
the library focuses on the study of common patterns in
linguistic structures.
It is worth examining two examples of English “morphology”, related to the production of regular and irregular plural nouns. Please notice how morphology is here between quotes: even though the output of this library has been used for real morphological studies, chiefly as a prior hypothesis to the segmentation of words into their constituents, we are not referring to morphemes in the proper grammatical sense of the study of word structures in terms of processes such as inflection or derivation. In the context of this documentation, “morpheme” is equivalent to a substring or set of substrings.
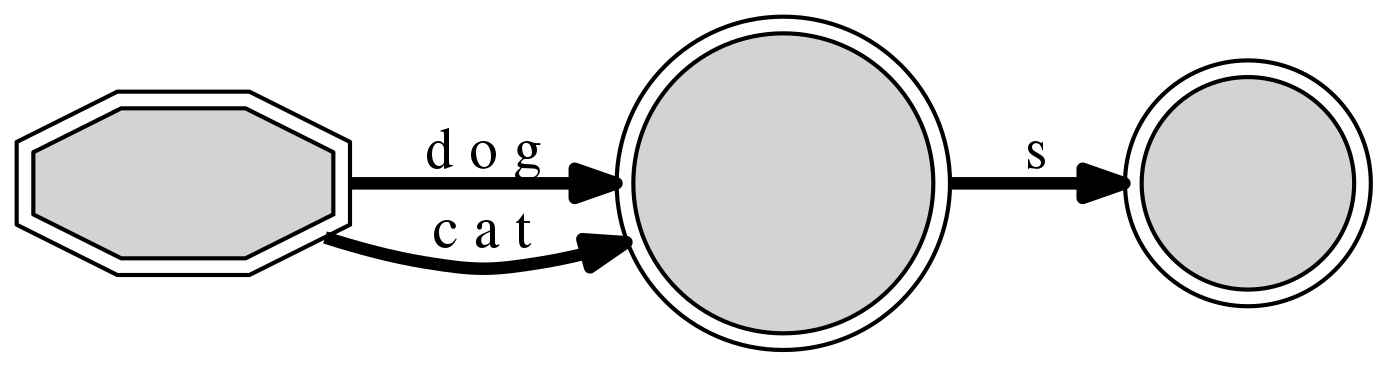
Let’s begin by creating a DAFSA involving the singular and plural forms
of two regular English nouns, “cat” and “dog”. As hoped, we obtain a
design with a final pass-through node (here, of index #3), showing us that
the paths can either end at this node (for singular forms) or
transition with an extra character s to the other final node (index #4),
producing the plural form.
DAFSA with 3 nodes and 3 edges (4 inserted sequences)
+-- #0: 0(#3/4:<c a t>/2|#3/4:<d o g>/2) [('d o g', 3), ('c a t', 3)]
+-- #3: F(#4/4:<s>/2) [('s', 4)]
+-- #4: F() []
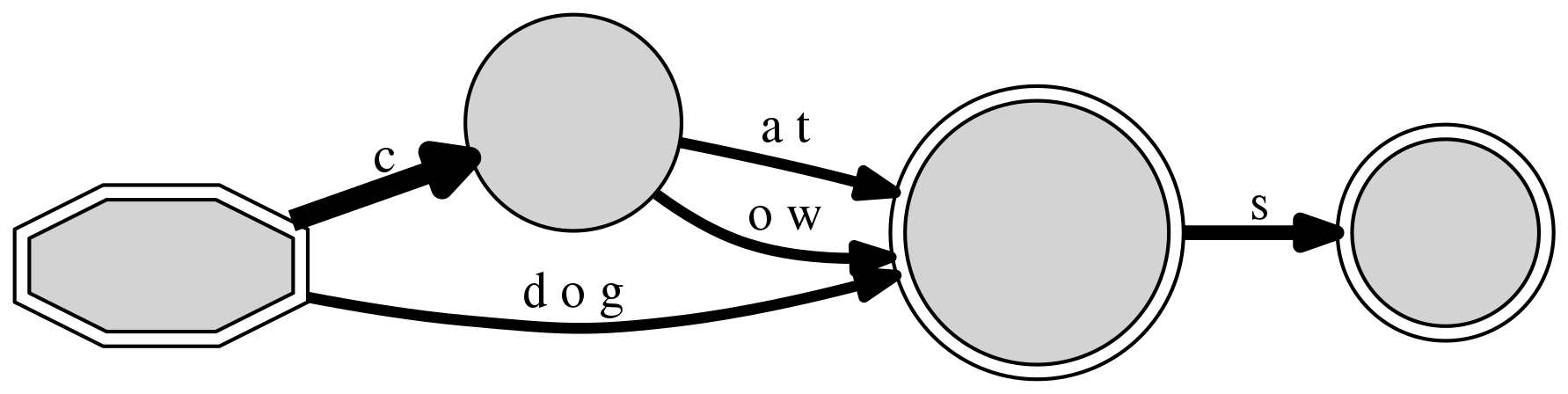
If we include another set of regular nouns (“cow” and “cows”), we
notice how the
global topography doesn’t change much, as again the paths can end at
node #3 or advance with a character s to node #4. Notice how the library
could further reduce the structure by identifying a shared initial
c between “cat” and “cow”: from linguistic studies, including cognates,
we know they are not the same morpheme in reality (they are not even a
morpheme), but they are shared material that should be investigated if
we knew nothing about the language under study.
DAFSA with 4 nodes and 5 edges (6 inserted sequences)
+-- #0: 0(#1/6:<c>/4|#3/6:<d o g>/2) [('c', 1), ('d o g', 3)]
+-- #1: n(#3/4:<a t>/2|#3/4:<o w>/2) [('a t', 3), ('o w', 3)]
+-- #3: F(#4/6:<s>/3) [('s', 4)]
+-- #4: F() []
Adding further pairs of regular nouns will increase the complexity of the
DAFSA, as they share less and less material, but would likewise highlight
recurrent elements that are potential constituents. The library informs such
frequencies in the textual representation, but the information is better
visualized in the graphical
output, with the size of the nodes and the width of the edges showing how
many times we visit each one. Here, the c shared by “cat” and “cow” is
less significant than the final s.
DAFSA with 5 nodes and 8 edges (10 inserted sequences)
+-- #0: 0(#1/10:<c>/4|#3/10:<d o g>/2|#17/10:<g i r a f f>/2|#17/10:<t u r t l>/2) [('t u r t l', 17), ('d o g', 3), ('c', 1), ('g i r a f f', 17)]
+-- #1: n(#3/4:<a t>/2|#3/4:<o w>/2) [('a t', 3), ('o w', 3)]
+-- #3: F(#4/10:<s>/5) [('s', 4)]
+-- #4: F() []
+-- #17: n(#3/4:<e>/4) [('e', 3)]
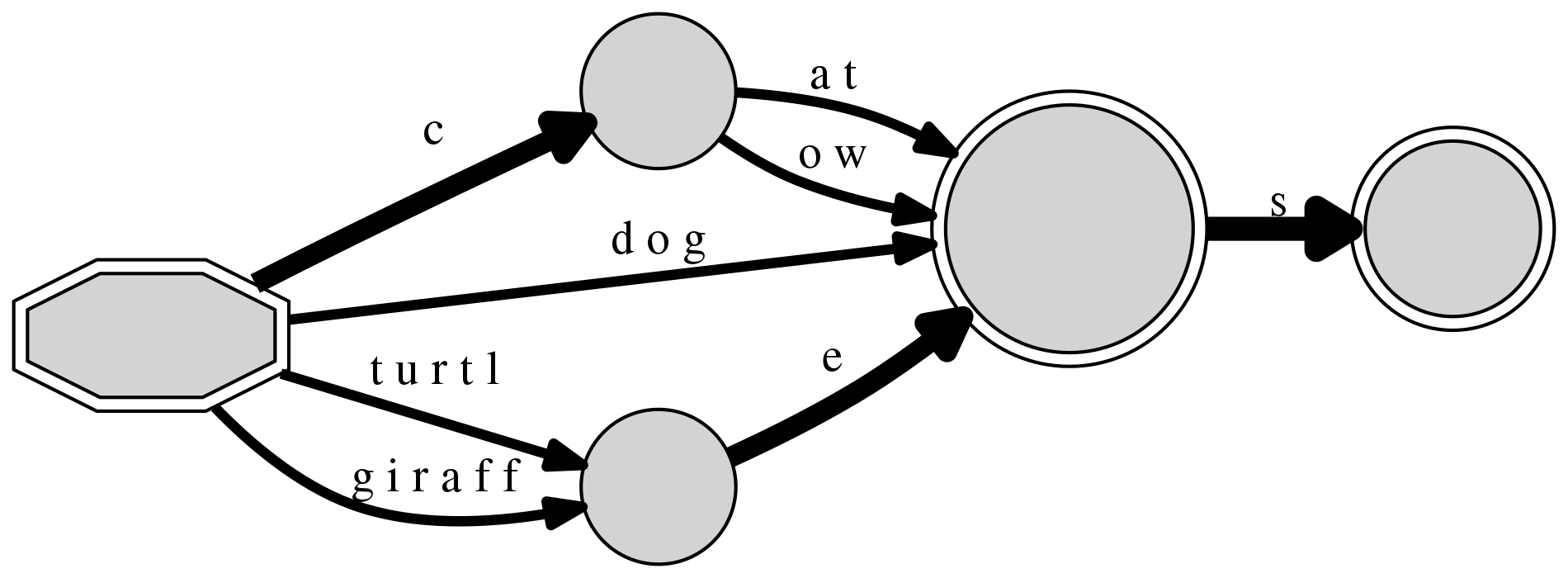
Including two pairs of irregular plurals, “goose/geese” and
“ox/oxen”, will highlight the differences with the previously
added words, as the final pass-through node for the plural with s,
the one of index #3, is not reachable in these cases.
DAFSA with 8 nodes and 14 edges (14 inserted sequences)
+-- #0: 0(#1/14:<c>/4|#3/14:<d o g>/2|#12/14:<g>/4|#29/14:<o x>/2|#21/14:<t u r t l>/2) [('o x', 29), ('d o g', 3), ('c', 1), ('g', 12), ('t u r t l', 21)]
+-- #1: n(#3/4:<a t>/2|#3/4:<o w>/2) [('a t', 3), ('o w', 3)]
+-- #3: F(#4/10:<s>/5) [('s', 4)]
+-- #4: F() []
+-- #12: n(#14/4:<e e>/1|#21/4:<i r a f f>/2|#14/4:<o o>/1) [('i r a f f', 21), ('e e', 14), ('o o', 14)]
+-- #14: n(#4/2:<s e>/2) [('s e', 4)]
+-- #21: n(#3/4:<e>/4) [('e', 3)]
+-- #29: F(#4/2:<e n>/1) [('e n', 4)]
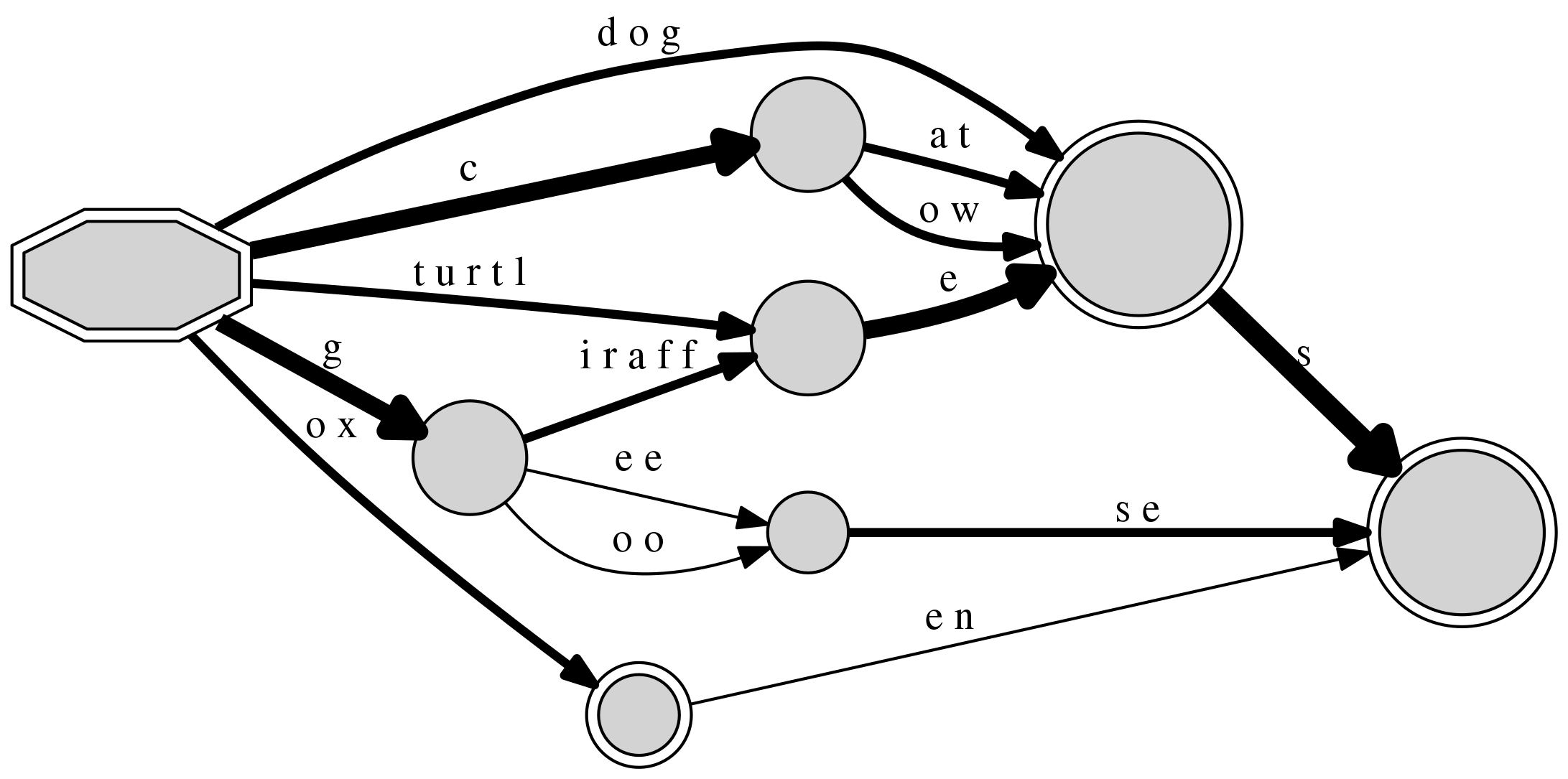
As a final development for this example, we can add pairs which are not
strictly regular, but which display a common pattern,
such as “man/men” and “woman/women”. The automata can identify this
structure, but notice how the graph also joins the
final n of “man” and “woman” to the final “n” of “oxen”.
We know from the history of the English language
that these are likewise unrelated, but once more
in the case of an unfamiliar language
we should examine this pattern as a “candidate morpheme”.
DAFSA with 10 nodes and 19 edges (18 inserted sequences)
+-- #0: 0(#1/18:<c>/4|#3/18:<d o g>/2|#12/18:<g>/4|#28/18:<m>/2|#34/18:<o x>/2|#21/18:<t u r t l>/2|#28/18:<w o m>/2) [('m', 28), ('w o m', 28), ('d o g', 3), ('o x', 34), ('c', 1), ('g', 12), ('t u r t l', 21)]
+-- #1: n(#3/4:<a t>/2|#3/4:<o w>/2) [('a t', 3), ('o w', 3)]
+-- #3: F(#4/10:<s>/5) [('s', 4)]
+-- #4: F() []
+-- #12: n(#14/4:<e e>/1|#21/4:<i r a f f>/2|#14/4:<o o>/1) [('i r a f f', 21), ('e e', 14), ('o o', 14)]
+-- #14: n(#4/2:<s e>/2) [('s e', 4)]
+-- #21: n(#3/4:<e>/4) [('e', 3)]
+-- #28: n(#29/4:<a>/2|#29/4:<e>/2) [('a', 29), ('e', 29)]
+-- #29: n(#4/5:<n>/5) [('n', 4)]
+-- #34: F(#29/2:<e>/1) [('e', 29)]
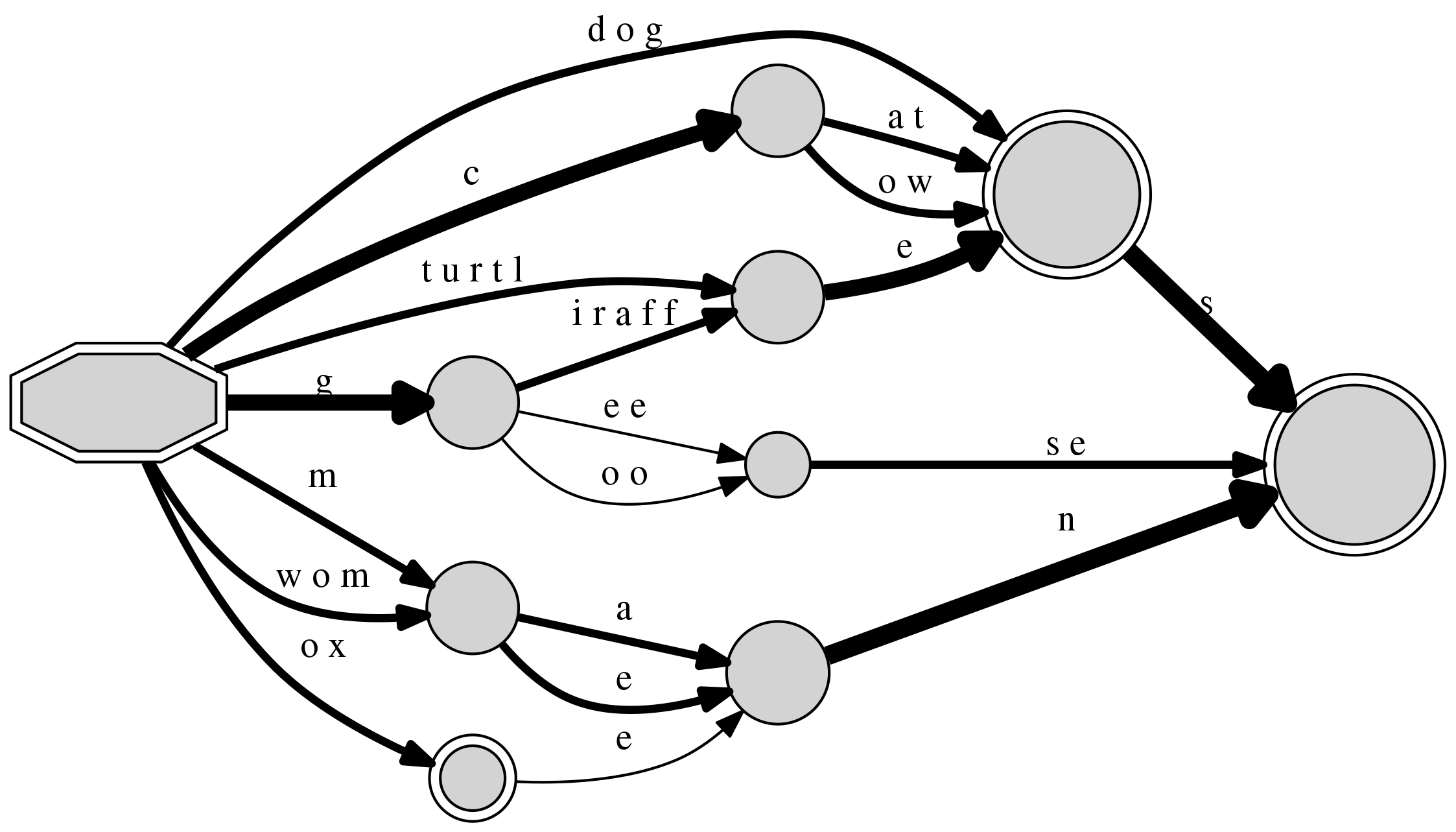
A DAFSA can highlight various regular processes concurrently.
If we decide to investigate different patterns for producing plurals, using
words ending with a sibilant
consonant (as “dish” and “witch”), words ending in o (as “hero” and
“potato”), and words ending in y (as “lady” and “sky”), besides
some simple cases of the previous example (“cat” and “dog”), the
processes of plural formation in English orthography are exposed.
DAFSA with 9 nodes and 16 edges (16 inserted sequences)
+-- #0: 0(#3/16:<c a t>/2|#5/16:<d>/4|#16/16:<h e r>/2|#22/16:<l a d>/2|#16/16:<p o t a t>/2|#22/16:<s k>/2|#7/16:<w i t c>/2) [('l a d', 22), ('h e r', 16), ('s k', 22), ('d', 5), ('w i t c', 7), ('p o t a t', 16), ('c a t', 3)]
+-- #3: F(#4/4:<s>/2) [('s', 4)]
+-- #4: F() []
+-- #5: n(#7/4:<i s>/2|#3/4:<o g>/2) [('o g', 3), ('i s', 7)]
+-- #7: n(#8/4:<h>/4) [('h', 8)]
+-- #8: F(#9/8:<e>/4) [('e', 9)]
+-- #9: n(#4/6:<s>/6) [('s', 4)]
+-- #16: n(#8/4:<o>/4) [('o', 8)]
+-- #22: n(#9/4:<i e>/2|#4/4:<y>/2) [('y', 4), ('i e', 9)]
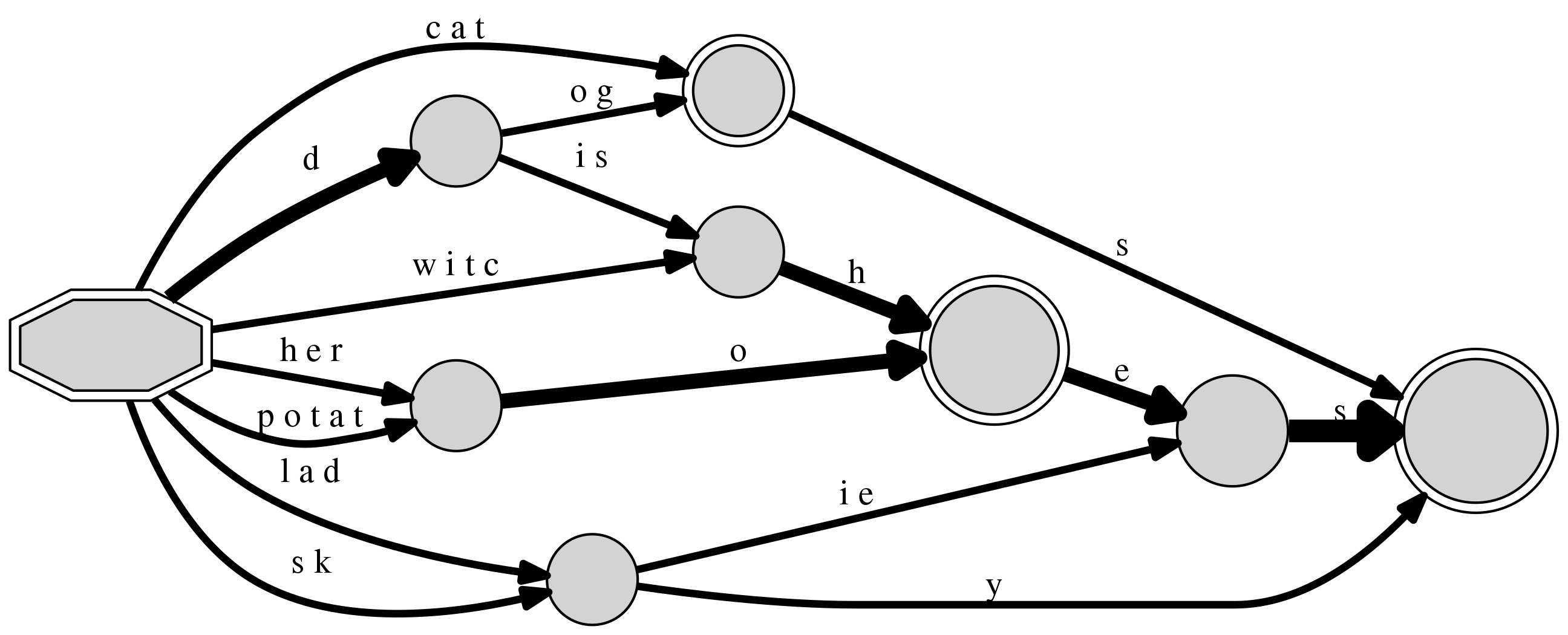
Manual inspection and study can quickly become intractable, notably in real studies considering phonological processes and when the strings also carry annotation tags (such as labels informing if each form is a singular or a plural). This is expected, because even though the output is designed to be human-readable and explorable, the automaton still works akin to a lossless compressor, not unlike grammar-based codes and the smallest grammar problem (despite operating on lists of sequences and not on single strings). For this reason, the library allows to export DAFSAs as graphs, allowing its output to be used by other software and for other purposes.